Dashboard Preview
Real-time Grafana dashboard with per-request visibility
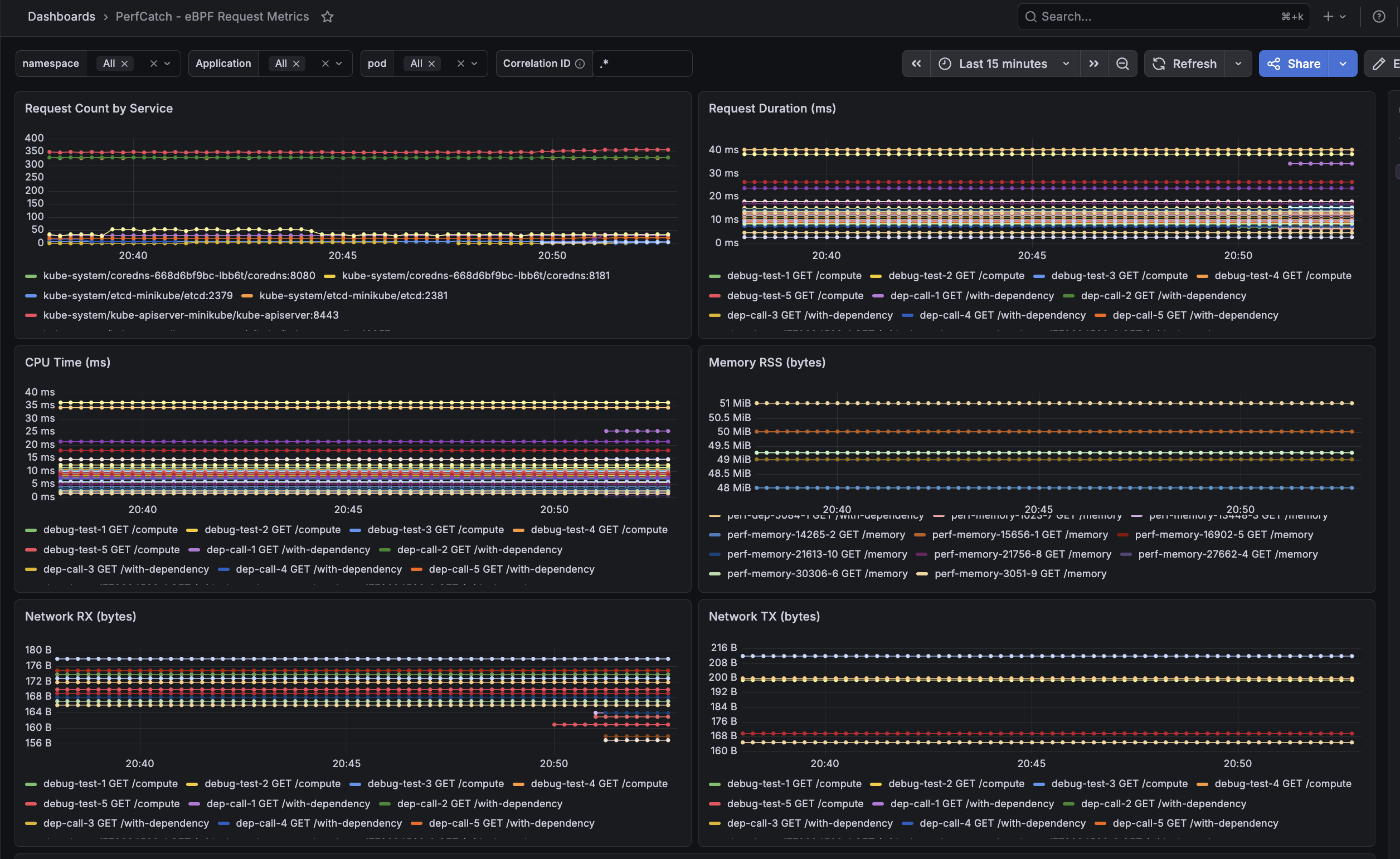
Grafana Dashboard — Time-Series Panels
6 panels showing Request Count by Service, Request Duration (ms), CPU Time (ms), Memory RSS (bytes), Network RX and TX bytes — all with per-pod granularity and correlation ID filtering.
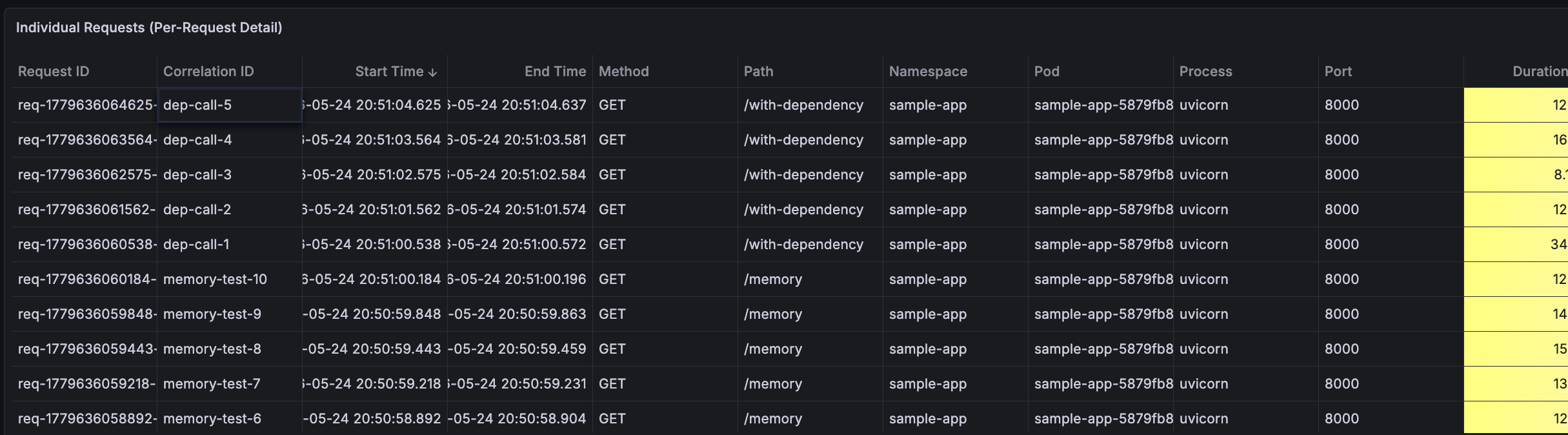
Per-Request Detail Table
Every individual request with Request ID, Correlation ID, Start/End Time, HTTP Method, Path, Namespace, Pod, and Process info.
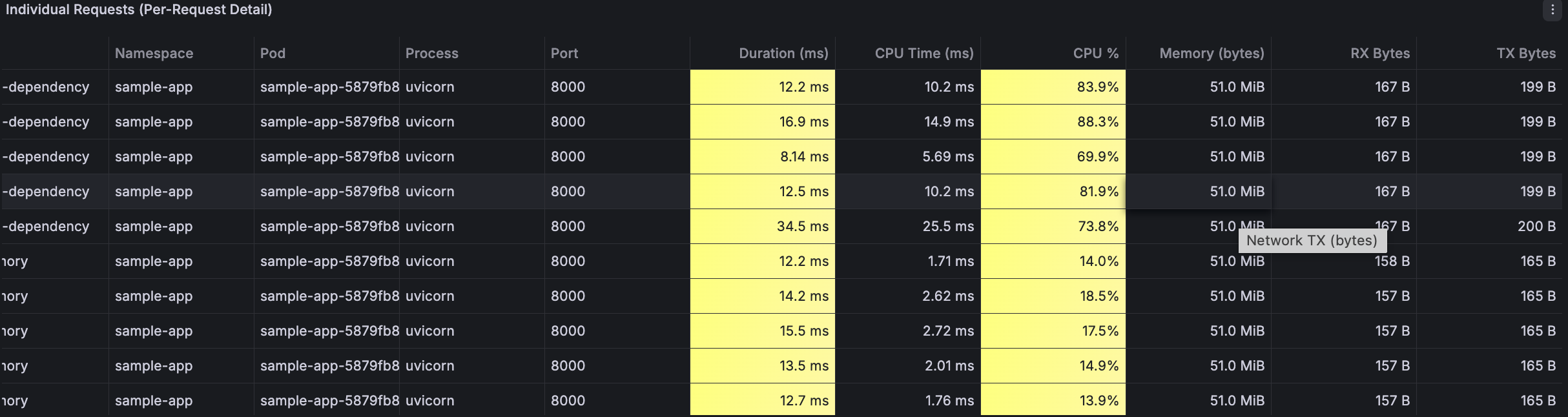
Resource Metrics per Request
Duration (ms), CPU Time (ms), CPU % utilization, Memory (bytes), Network RX and TX bytes — color-coded for quick anomaly detection.